一、MLIR简介
下面这张图分为高级编程语言和机器学习框架两个部分。
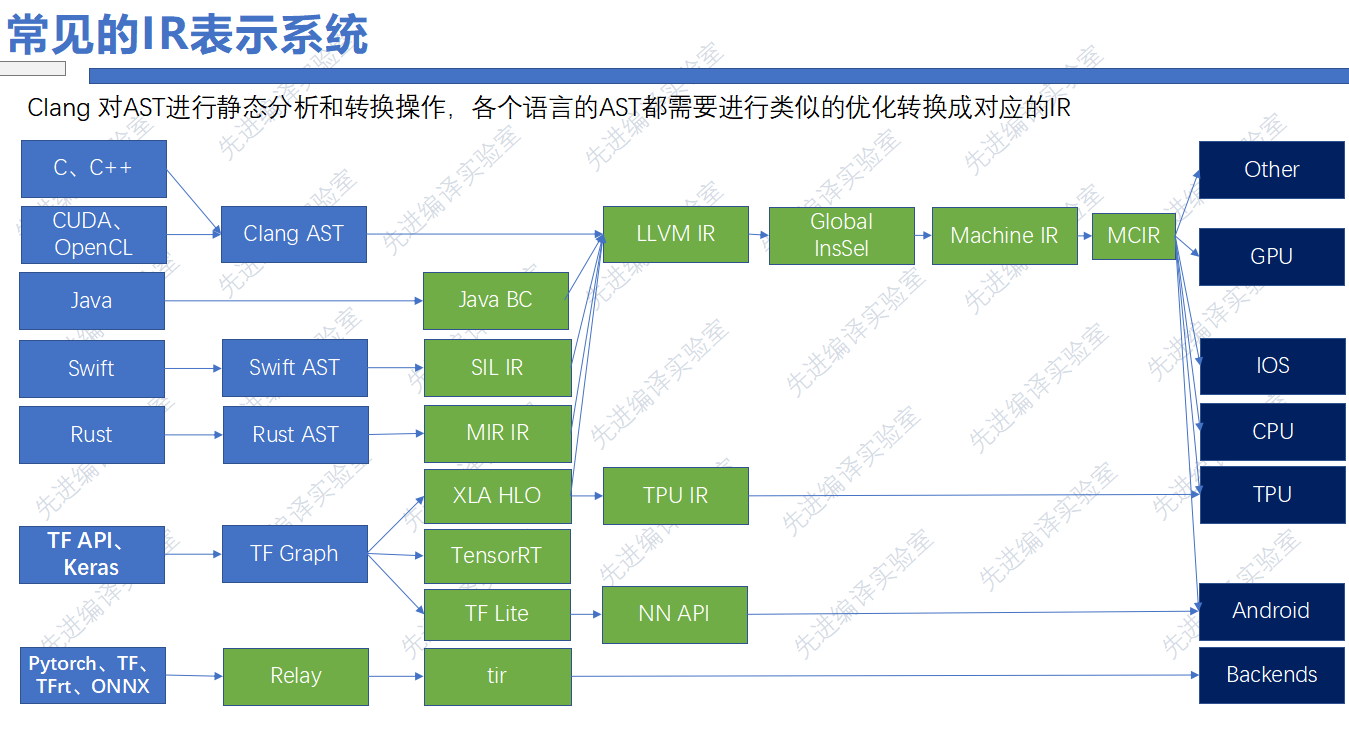
以C语言为例,在编译阶段,会由前端Clang编译生成抽象语法树(AST),AST之后会被转换成LLVM IR,再转换成机器码,在指定的机器上运行。值得注意的是,C语言在转换成LLVM IR之前,不会进行特定语言的优化,程序的优化,主要集中在LLVM IR阶段,它会丢失很多信息,也会带来优化不充分的问题。
Java语言不会生成AST,而是将Java代码转换成Java字节码,这是一种内部IR,他可以进行自己语言的优化,在此之后Java字节码会转换成LLVM IR,进一步的优化,根据LLVM后端进一步的转换成字节码。
Swift语言转换成AST之后,也会创建自己语言的IR,这种方式也被Rust等语言采用。
不仅在高级语言中,在深度学习框架中也有类似的情况,如TensorFlow框架,会先转化成图IR,进一步转换成针对某个硬件的IR表示,如针对TPU,手机设备等,面对这种情况,开发人员需要进行不同的IR设计以及针对这种IR的优化。
但是随着IR种类的增多,会出现一些问题:
- 针对不同种类的IR开发的Pass优化可能重复,也就是不同的IR的同类Pass不兼容,针对新的IR编写同类的Pass需要重新学习IR语法,门槛过高
- 不同类型的IR所做的Pass优化在下一层中不可见,各种IR都想在当前层中优化做的更好,这就会导致优化的重复,导致效率偏低。
- 不同类型IR间转换开销大,从图IR到LLVM IR直接转换存在较大的开销,比如从图IR转换到LLVM IR 。
因此, TensorFlow团队提出了MLIR,它希望作为一种编译器的基础设施,将编译流程中的各个层次的IR进行统一的表示,降低新加入的前端语言或是后端硬件构建编译器的成本,帮助现在已有的编译器连接在一起,进行复用。
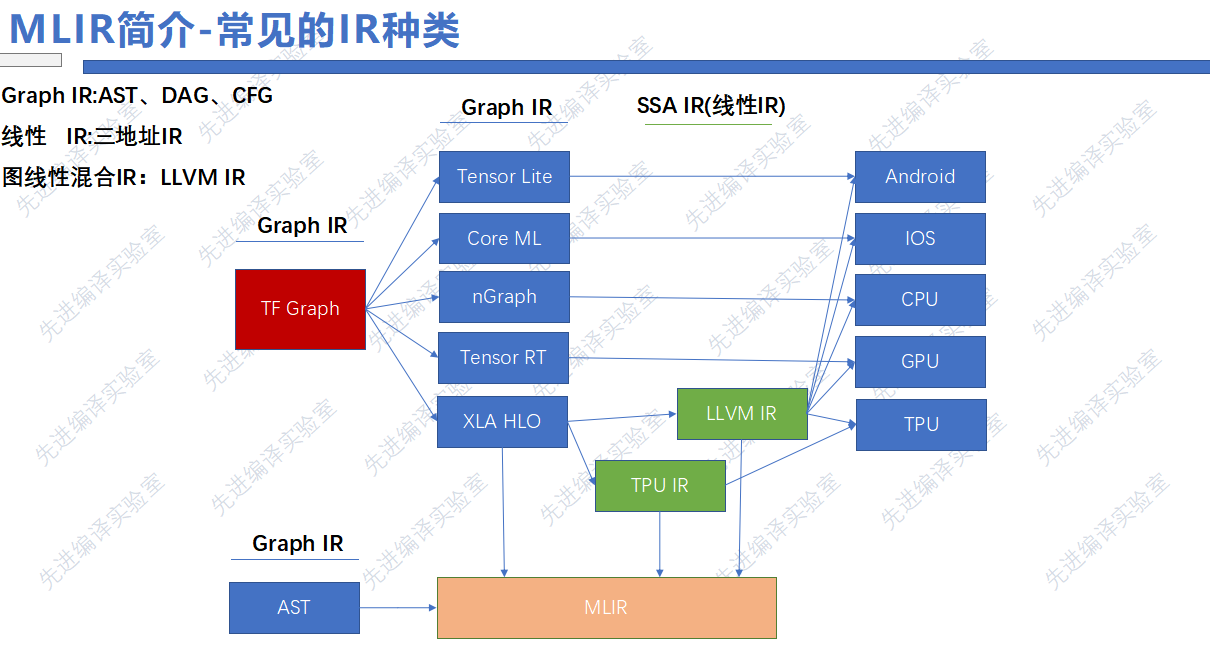
MLIR中最重要的概念是它的Dialect方言系统。
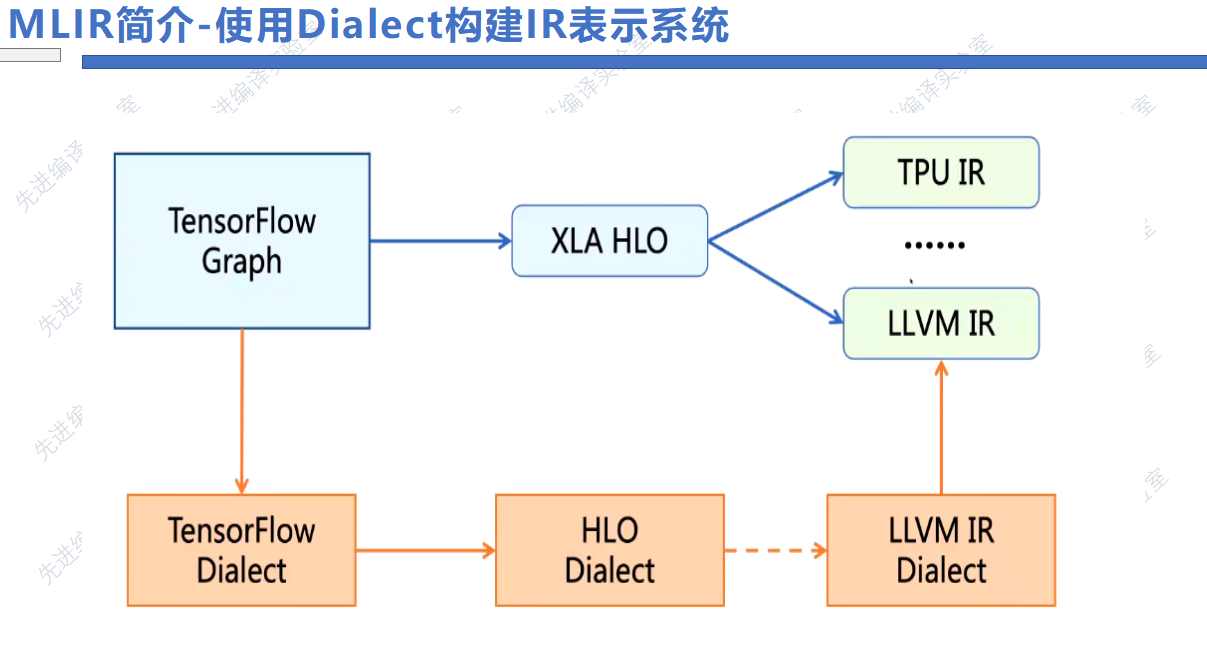
Dialect其实是表示一种层次的IR,将各种IR转换成对应的MLIR Dialect。
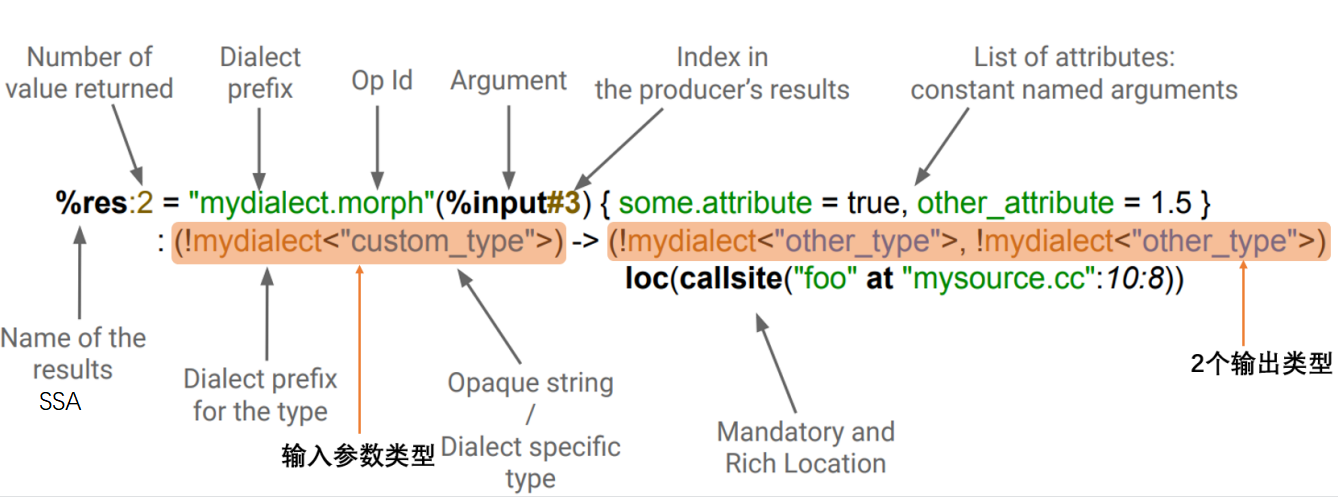
MLIR Dialect
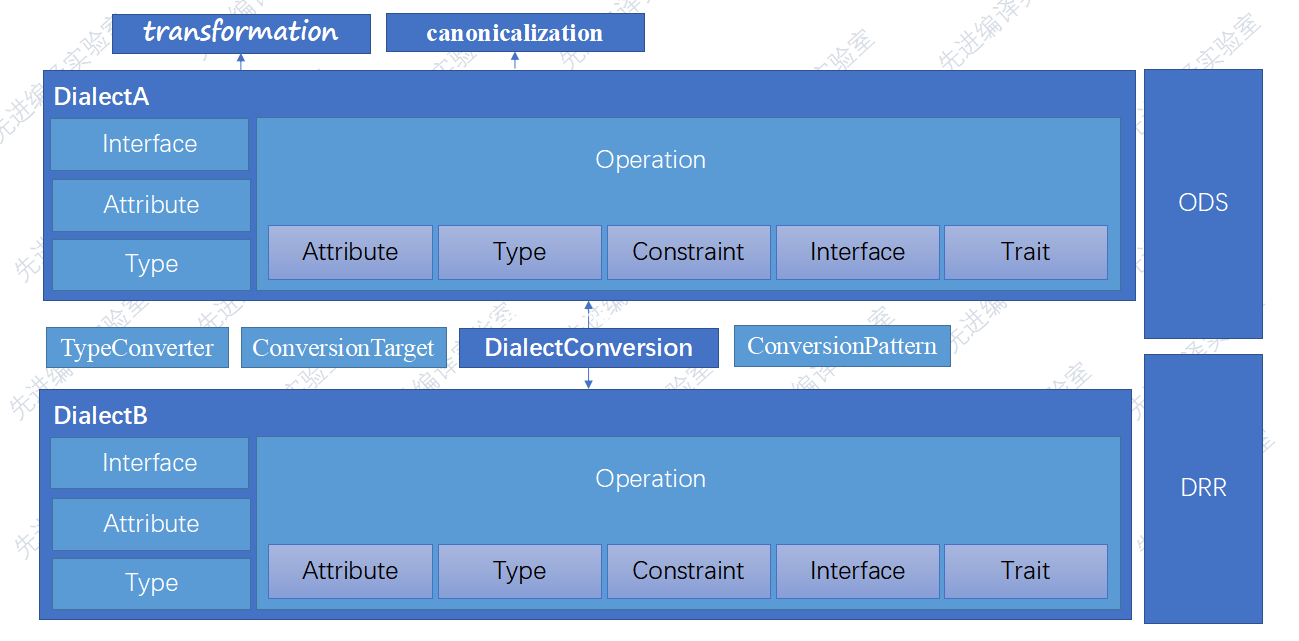
一个 MLIR dialect 包括 :
- 命名空间
- 一组自定义类型
- 一组 operations,这是核心元素
- 解析器、打印器
- 优化(pass): analysis, transformations, dialect conversions.
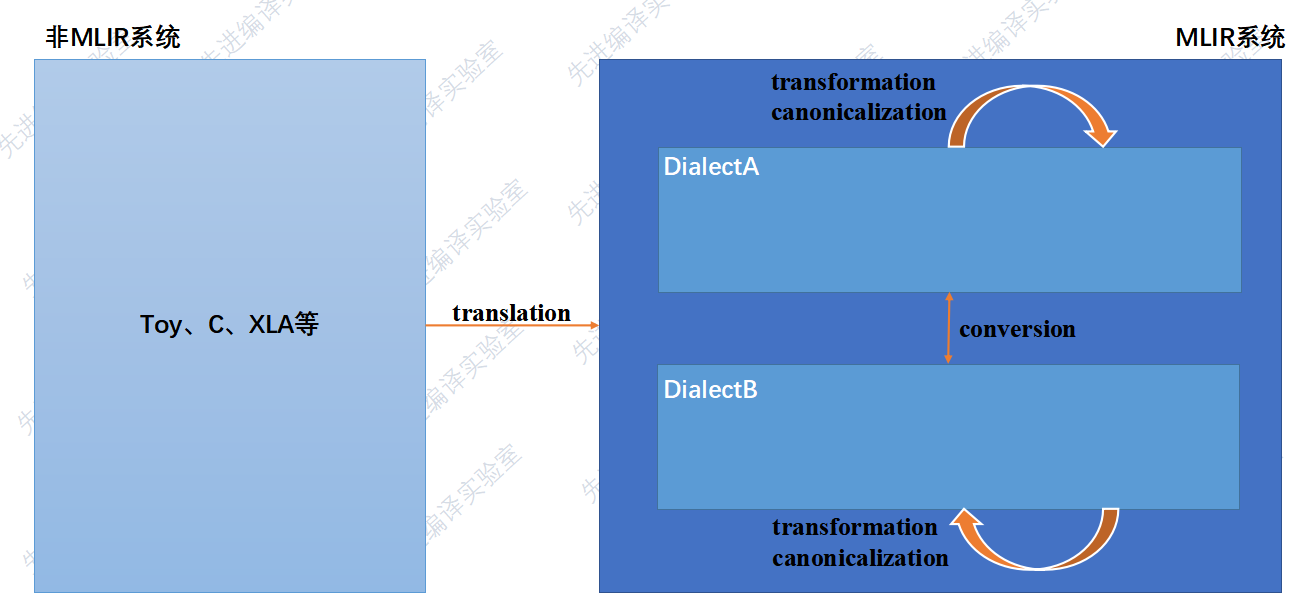
conversion : Dialect之间的转换
可以利用mlirGen模块来遍历AST,生成对应的Toy Dialect的MLIR表达式,那么builder创建的operation是从哪来的?以及Toy Dialect是从哪来的?针对这两个问题,我们需要了解MLIR系统是如何引用自定义的Dialect和其中的一些Operation
后面ODS框架有点没听懂
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1149440709@qq.com

